Articles
Predictive Maintenance: I’ll have what she’s having…
For years, data rich industries such as telecommunications and banking have been working with vast amounts of customer information. Uncovering value from this has brought many challenges. Advanced analytical techniques, such as data mining through machine learning, or applied statistical algorithms have long set the standard for making the best out of all this information. Specifically predictive customer behaviour – by uncovering hidden patterns and putting the insights into action.
This happens every day. From alternative product offerings when you make a purchase online, to split second settlement decisions for insurance claims, predictive analytics has had and continues to have a transformative effect on business in the modern technological era. The speed at which these decisions are made, the sheer volume of decisions and their importance is ever increasing too.
With big data and the internet of things very much established at this point, what does this mean for operational efficiencies and maintenance operations? No longer is Predictive Analytics confined to the customer experience. No longer is Predictive Analytics confined to the traditional industries. Manufacturing, Building and Facilities management organisations and Smarter Cities are now using Predictive Analytics to make sense of the terabytes of information they collect on a daily basis.
Predictive Maintenance is one example of this – using data mining and statistical algorithms to predict asset failure and optimise asset lifetime. Actually it’s nothing new. Data rich organisations have been using similar Predictive Analytics techniques for years and years. What’s new here is that more and more data is becoming accessible in new industries.
Predictive Maintenance can deliver huge cost saving results. For example, reducing maintenance costs of unplanned downtime by 60-90%, reducing excess capacity to compensate downtime by up to 90%, reducing scrap or re-work by 50% and extending asset lifetime by between 5% and 15%. Data forms the basis of all these results, but let’s look at what kinds of data are used.
The Who? What? Where? When? And Why?
Let’s think again about the traditional, long established, customer orientated analytics to predict customer behaviour ahead of time. The potential data held for a customer is numerous.
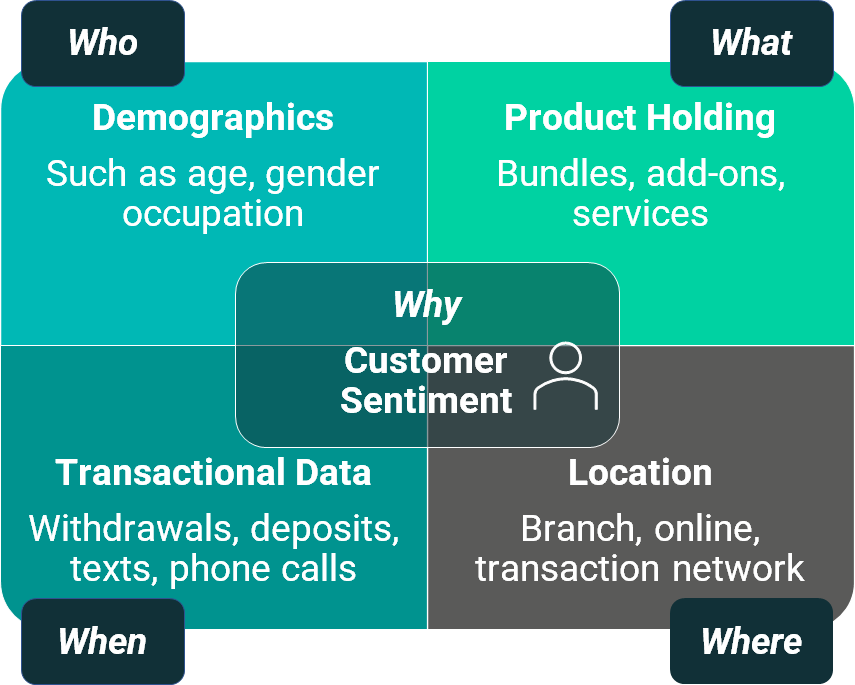
Of course, we don’t need all this information to produce valuable insights. Very many successful predictive analytics projects have been implemented without data in all of these areas. The Why element is often obtained through market research methods or linked to an NPS initiative, but is increasingly vital to understanding customer behaviour.
The A.E.I.O. and U
What’s does this look like for Predictive Maintenance for Assets though? Well, the answer is that it’s not entirely different. Rather than producing a 360-degree view of a customer, we are looking at an asset, but you can still strive to build a complete picture. For example:

Instead of the Why before, the U completes the picture! It is only complete when you have developed an understanding of the data elements that you have. Without the option to directly ask an asset about its opinions, we lean even more heavily on the advanced algorithms to uncover hidden insights.
Similar to the customer experience applications, you don’t need all the data to get results. And similar to customer experience the data need not all be in easily accessible formats. Maintenance logs and asset histories are very often recorded in an unstructured way. The great news is that this part of the Predictive Analytics world, is ready-built, and ready-tested in other industries. Algorithms have been developed to mine unstructured, free text data, and extract meaningful insights rapidly, and are being used extensively.
Indeed, asset maintenance, facilities management, building management and other similar industries are all innovating today by borrowing from other historically data rich industries and using predictive analytics. The types of data are not the same, but then again, they aren’t so different either!
Version 1’s experienced consultants are on hand to help you understand your SPSS needs – from consultancy and training to finding the best software and license type for your analytical and usage requirements. Contact us to discuss your requirement and identify the best SPSS solution for you.

Related Articles
Take a look through our SPSS Articles covering a broad range of SPSS product and data analytics topics.

